JAVA线程池的一些琐事
JAVA线程池的一些琐事
1. 概述
焦点:
- 为什么要有线程池?
- java如何创建线程池,区别是什么?
- 几个思考的问题?
2.为什么要有线程池?
多线程特点:
- 资源占用多
- 默认一个线程的栈 1M(-Xss可配)(note: 堆外,栈溢出)
- 需要上下文切换
- cpu切换之前的状态存储(pc,寄存器等)
线程池(资源池)都是为了解决一个主要问题:创建线程(资源)和销毁线程(资源)的成本,比维护 线程(资源)池 的成本高。
延伸可解决的问题:
- 限制程序对资源无限申请
- 可管理,可监控
对比:协程(内存8k),线程成本更高,线程池就成了常用手段之一
3. java如何创建线程池?
创建线程池的方法:
- new ThreadPoolExecutor()
- Executors.newXXXX()
Executors.newXXXX() 是 对 new ThreadPoolExecutor() 提供的封装
3.1 ThreadPoolExecutor
java中的线程池 ThreadPoolExecutor
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize >= 0 && maximumPoolSize > 0 && maximumPoolSize >= corePoolSize && keepAliveTime >= 0L) {
if (workQueue != null && threadFactory != null && handler != null) {
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
} else {
throw new NullPointerException();
}
} else {
throw new IllegalArgumentException();
}
}
public void execute(Runnable command) {
if (command == null) {
throw new NullPointerException();
} else {
int c = this.ctl.get();
if (workerCountOf(c) < this.corePoolSize) { // 当前worker数量 < corePoolSize,将添加一个worker线程来工作
if (this.addWorker(command, true)) {
return;
}
c = this.ctl.get();
}
if (isRunning(c) && this.workQueue.offer(command)) { // 当前worker数量 >= corePoolSize, 将多余的任务放到 worker 队列中
int recheck = this.ctl.get();
if (!isRunning(recheck) && this.remove(command)) {
this.reject(command);
} else if (workerCountOf(recheck) == 0) {
this.addWorker((Runnable)null, false);
}
} else if (!this.addWorker(command, false)) { // 如果 使用 worker 队列放不下,且 也无法增加worker线程的数量(达到maximumPoolSize)了,就执行拒绝
this.reject(command);
}
}
}
/**
* 添加worker线程(core = true :占用 corePoolSize 线程的名额;core = false :占用 maximumPoolSize-corePoolSize 线程的名额)
**/
private boolean addWorker(Runnable firstTask, boolean core) {}
BlockingQueue 有什么?
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
- LinkedBlockingQueue:一个基于链表结构的无界阻塞队列(capacity=2147483647),此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue。
- PriorityBlockingQueue:一个具有优先级的无界阻塞队列(capacity=2147483647), 内部使用PriorityQueue。
RejectedExecutionHandler 有什么?
- ThreadPoolExecutor.AbortPolicy 如果元素添加到线程池中失败,则直接抛运行时异常 RejectedExecutionException(默认)
- ThreadPoolExecutor.DiscardPolicy 如果元素添加线程池失败,则放弃,不抛异常。
- ThreadPoolExecutor.CallerRunsPolicy 如果元素添加线程池失败,则主线程自己来运行任务。
- ThreadPoolExecutor.DiscardOldestPolicy 如果元素添加线程池失败,会将队列中最早的元素删除之后,再尝试添加,一直重复成功为止。
3.2 Executors.newXXXX()

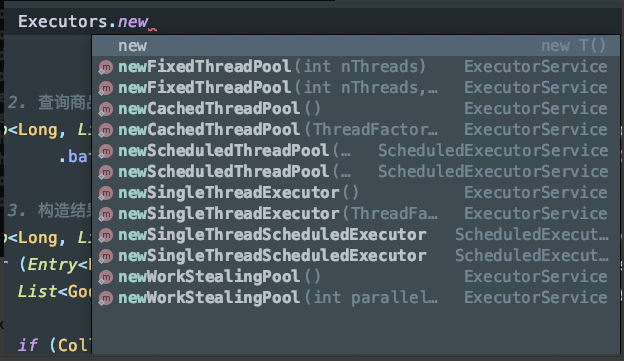
这些都啥区别?
- java.util.concurrent.Executors#newFixedThreadPool(int)
// core size 和 max size 一样大,无界队列
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue(), threadFactory);
}
- java.util.concurrent.Executors#newCachedThreadPool()
// 无队列,来一个任务,开一个线程,直到 oom (内部逻辑,2147483647 之后就手动oom异常)
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, 2147483647, 60L, TimeUnit.SECONDS, new SynchronousQueue());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, 2147483647, 60L, TimeUnit.SECONDS, new SynchronousQueue(), threadFactory);
}
- java.util.concurrent.Executors#newSingleThreadExecutor()
// core 和 max 都是1,无界队列
public static ExecutorService newSingleThreadExecutor() {
return new Executors.FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new Executors.FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue(), threadFactory));
}
- java.util.concurrent.Executors#newScheduledThreadPool(int)
// 定时执行的线程池
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new Executors.DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new Executors.DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1, threadFactory));
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
- java.util.concurrent.Executors#newWorkStealingPool(int)
// 支持工作窃取的线程池
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool(parallelism, ForkJoinPool.defaultForkJoinWorkerThreadFactory, (UncaughtExceptionHandler)null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool(Runtime.getRuntime().availableProcessors(), ForkJoinPool.defaultForkJoinWorkerThreadFactory, (UncaughtExceptionHandler)null, true);
}
4. 几个思考的问题
4.1 核心线程怎么保活
使用阻塞队列(这就是为什么就算空队列,也一定要传入 workQueue 这个参数)。getTask 是每个worker线程,获取自己要执行的任务。
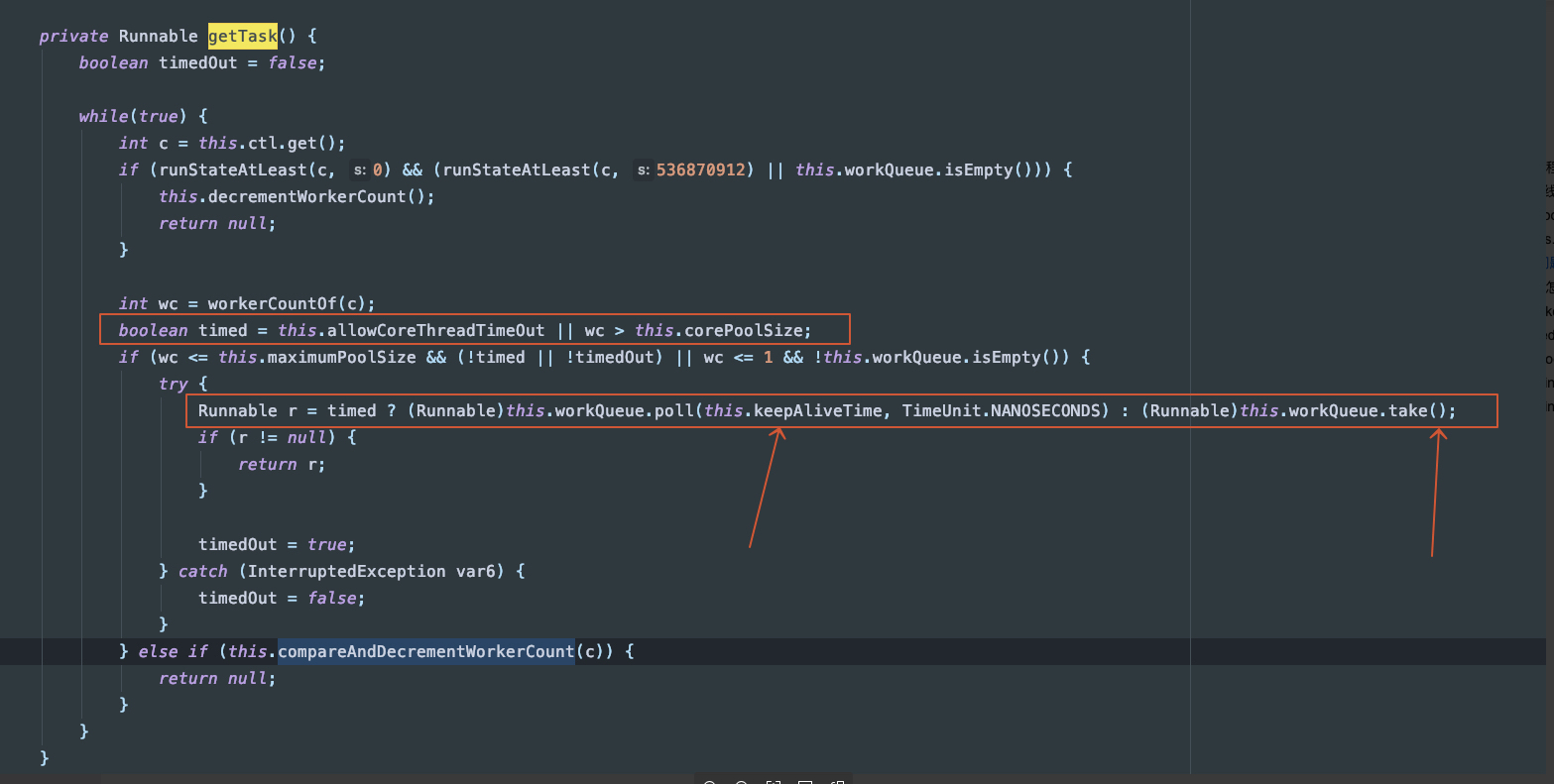
4.2 怎么实现keepAliveTime的
同上 blockQueue 的 poll
4.3 ScheduledExecutorService怎么实现任务定时执行
构造函数:
// core size 传入,max size = 2147483647, workQueue = ScheduledThreadPoolExecutor.DelayedWorkQueue()
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, 2147483647, 10L, TimeUnit.MILLISECONDS, new ScheduledThreadPoolExecutor.DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory) {
super(corePoolSize, 2147483647, 10L, TimeUnit.MILLISECONDS, new ScheduledThreadPoolExecutor.DelayedWorkQueue(), threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize, RejectedExecutionHandler handler) {
super(corePoolSize, 2147483647, 10L, TimeUnit.MILLISECONDS, new ScheduledThreadPoolExecutor.DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, 2147483647, 10L, TimeUnit.MILLISECONDS, new ScheduledThreadPoolExecutor.DelayedWorkQueue(), threadFactory, handler);
}
ScheduledThreadPoolExecutor.DelayedWorkQueue: 相当于DelayQueue和PriorityQueue的结合体。(权重是 下次执行的时间),无界队列
delayQueue 是什么?是一个BlockingQueue,用于放置实现了Delayed接口的对象,其中的对象只能在其到期时才能从队列中取走。
class MyDelayedTask implements Delayed{
private String name ;
private long start = System.currentTimeMillis();
private long time ;
public MyDelayedTask(String name,long time) {
this.name = name;
this.time = time;
}
/**
* 需要实现的接口,获得延迟时间, 0的时候,就表示可以用了
*/
@Override
public long getDelay(TimeUnit unit) {
return unit.convert((start+time) - System.currentTimeMillis(),TimeUnit.MILLISECONDS);
}
/**
* 用于延迟队列内部比较排序 当前时间的延迟时间 - 比较对象的延迟时间
*/
@Override
public int compareTo(Delayed o) {
MyDelayedTask o1 = (MyDelayedTask) o;
return (int) (this.getDelay(TimeUnit.MILLISECONDS) - o.getDelay(TimeUnit.MILLISECONDS));
}
@Override
public String toString() {
return "MyDelayedTask{" +
"name='" + name + '\'' +
", time=" + time +
'}';
}
}
常用方法:

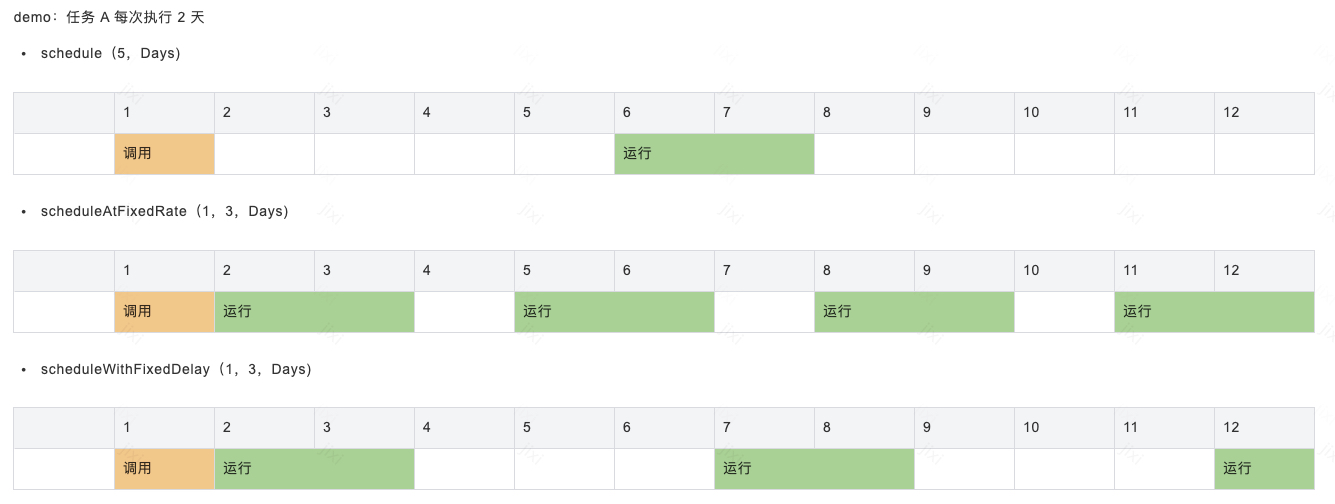
注意:execute 并不会实现延迟效果(因为execute是线程池通用方法,仍然依赖 先core, 后queue, 再max, 最后reject)
问题:schedule,scheduleAtFixedRate,scheduleWithFixedDelay 是如何实现延迟的?
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) {
if (command != null && unit != null) {
RunnableScheduledFuture<Void> t = this.decorateTask((Runnable)command, new ScheduledThreadPoolExecutor.ScheduledFutureTask(command, (Object)null, this.triggerTime(delay, unit), sequencer.getAndIncrement())); // 根据 任务(command)构建一个 延迟任务对象
this.delayedExecute(t); // 延迟执行这个任务
return t;
} else {
throw new NullPointerException();
}
}
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (this.isShutdown()) {
this.reject(task);
} else {
super.getQueue().add(task); // 直接将任务加到 workQueue 里面,所以 ScheduledThreadPoolExecutor 是 先queue,再core,再max,在reject
if (!this.canRunInCurrentRunState(task) && this.remove(task)) {
task.cancel(false);
} else {
this.ensurePrestart();
}
}
}
scheduleAtFixedRate 和 scheduleWithFixedDelay 流程一样,但是延迟任务对象 构造出来的不一样
4.4 ForJoinPool
4.4.1 什么是 forkjoin 什么是 mapreduce
forkjoin 和 mapreduce 都是分治的思想。
举例子:
- forkjoin: 1+2+3+4+5+6 => ((1+2+3)+(4+5+6)) => (((1+2)+(3))+((4+5)+(6)))
- 递归拆分
- 拆分之后 块与块之间仍然有联系
- 单机
- mapreduce: 1+2+3+4+5+6 => sum((1+2), (5+6), (3+4))
- 拆分一次,随机拆分,拆分成目标大小的块即可
- reduce 也是随机的,块与块之间 不存在联系
- 分布式
forkjoin模式:
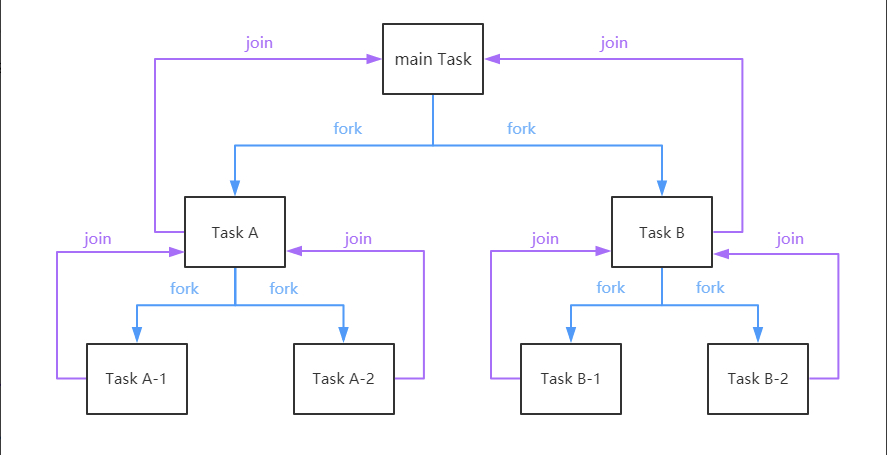
4.4.2 什么是 work staling
核心思想: work stealing 工作窃取
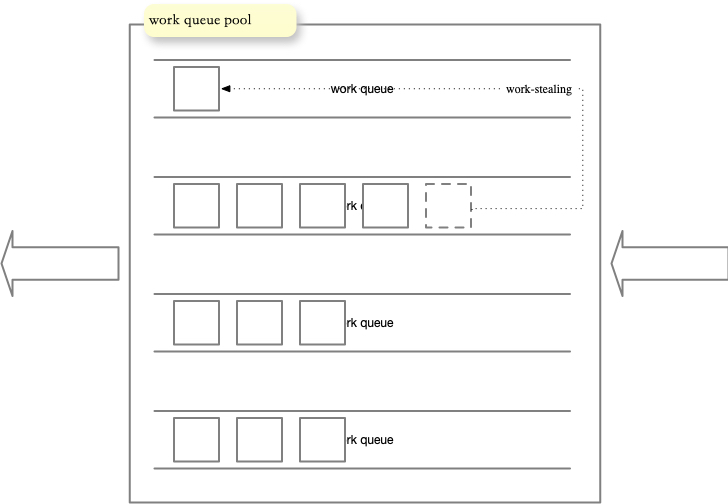
充分利用线程进行并行计算,减少线程间的竞争(在某些情况下还是会存在竞争,比如双端队列里只有一个任务时)。
4.4.3 Java ForkJoinPool
在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),工作线程优先处理来自自身队列的任务(LIFO或FIFO顺序,参数 mode 决定),然后以FIFO的顺序随机窃取其他队列中的任务。
具体思路如下:
- 每个线程都有自己的一个WorkQueue,该工作队列是一个双端队列。
- 队列支持三个功能push、pop、poll
- push/pop只能被队列的所有者线程调用,而poll可以被其他线程调用。
- 划分的子任务调用fork时,都会被push到自己的队列中。
- 默认情况下,工作线程从自己的双端队列获出任务并执行。
- 当自己的队列为空时,线程随机从另一个线程的队列末尾调用poll方法窃取任务。
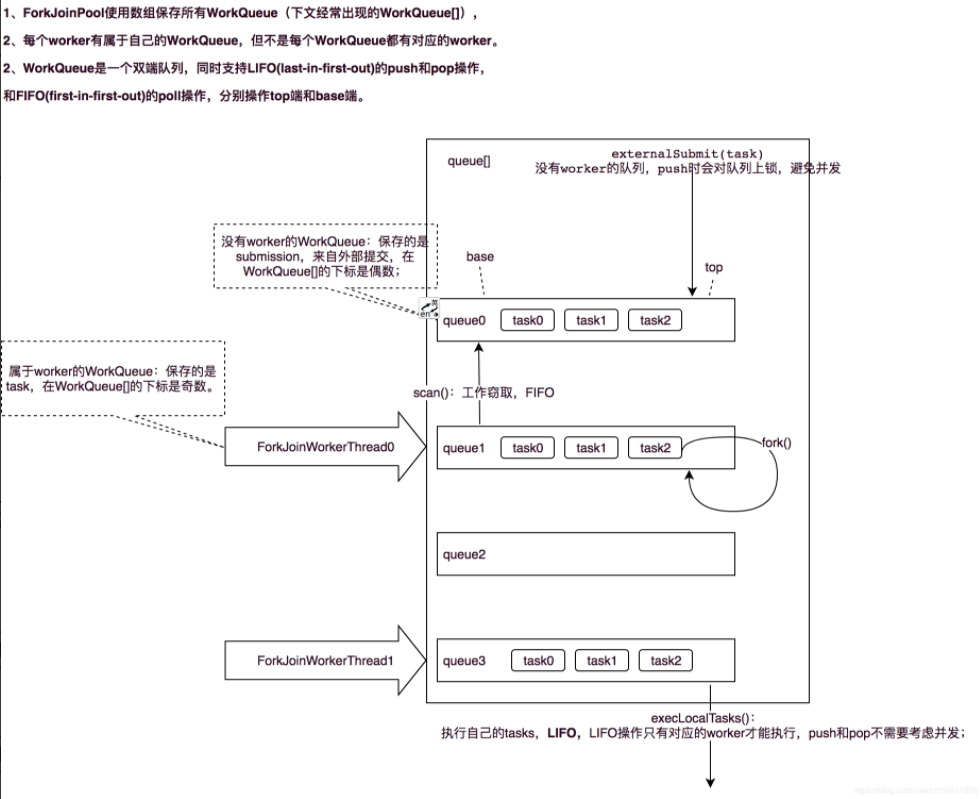
4.4.4 java 怎么使用 ForkJoinPool
Fork/Join框架主要包含三个模块:
- 任务对象: ForkJoinTask (包括RecursiveTask、RecursiveAction 和 CountedCompleter)
- 执行Fork/Join任务的线程: ForkJoinWorkerThread
- 线程池: ForkJoinPool
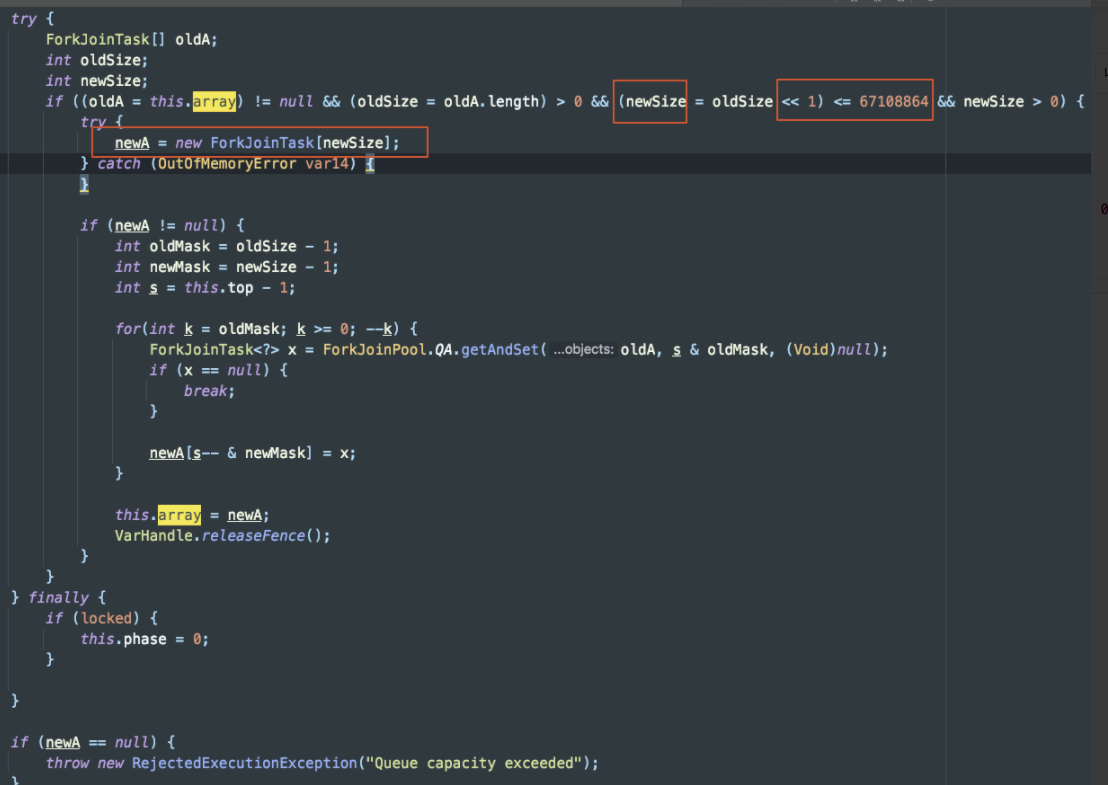
ForkJoinPool 只接收 ForkJoinTask 任务(在实际使用中,也可以接收 Runnable/Callable 任务,但在真正运行时,也会把这些任务封装成 ForkJoinTask 类型的任务),RecursiveTask 是 ForkJoinTask 的子类,是一个可以递归执行的 ForkJoinTask,RecursiveAction 是一个无返回值的 RecursiveTask,CountedCompleter 在任务完成执行后会触发执行一个自定义的钩子函数。
import java.util.concurrent.RecursiveTask;
public class CountTask extends RecursiveTask<Long> {
private int start;
private int end;
private int limit;
public CountTask(int start, int end, int limit) {
this.start = start;
this.end = end;
this.limit = limit;
}
@Override
protected Long compute() {
long sum = 0;
if (end - start < limit) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
int mid = (start + end) / 2;
CountTask countTask1 = new CountTask(start, mid, limit);
CountTask countTask2 = new CountTask(mid + 1, end, limit);
countTask1.fork();
countTask2.fork();
Long result1 = countTask1.join();
Long result2 = countTask2.join();
sum = result1 + result2;
}
return sum;
}
}
public class Main {
public static void main(String[] args) {
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask countTask = new CountTask(1, 1000000, 5);
Long invoke = forkJoinPool.invoke(countTask);
long end = System.currentTimeMillis();
System.out.println(invoke + "," + (end - start));
}
}
// 500000500000,126
提交任务的区别:
- invoke()会等待任务计算完毕并返回计算结果;
- execute()是直接向池提交一个任务来异步执行,无返回结果;
- submit()也是异步执行,但是会返回提交的任务,在适当的时候可通过task.get()获取执行结果。
4.4.5 ForkJoinPool 的核心参数
核心线程数:
- 默认线程数 Runtime.getRuntime().availableProcessors()
- 最小线程数 1
// 默认 Runtime.getRuntime().availableProcessors() ,cpu线程数
// 最大 32767
// keepAlive 60000 ms
public ForkJoinPool() {
this(Math.min(32767, Runtime.getRuntime().availableProcessors()), defaultForkJoinWorkerThreadFactory, (UncaughtExceptionHandler)null, false, 0, 32767, 1, (Predicate)null, 60000L, TimeUnit.MILLISECONDS);
}
队列大小: