单品活动-C端架构演进和稳定性建设
单品活动-C端架构演进和稳定性建设
说在前面,在这个领域工作整三年了,在技术和业务上有些总结,这篇文章就是总结篇之一。
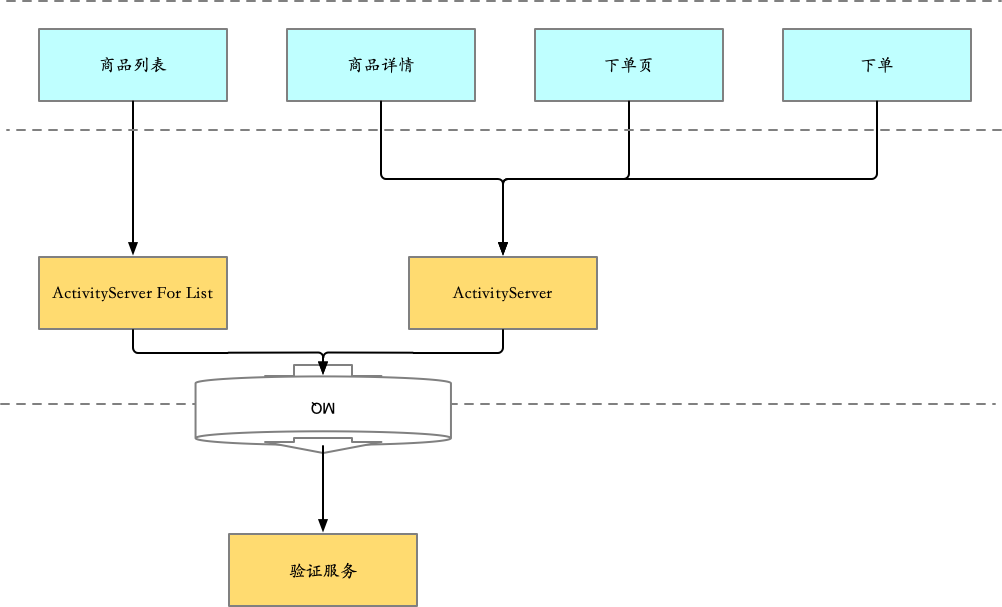
0 框架图
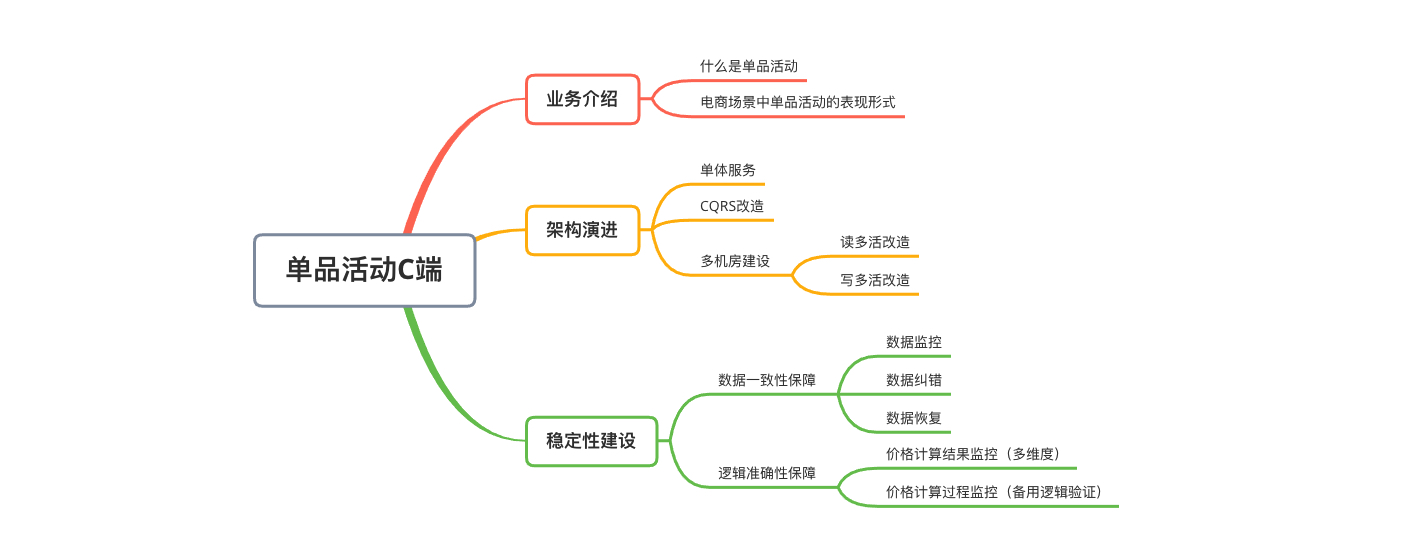
1 业务介绍
1.1 什么是单品活动
电商中的活动,最直接感受,是反应出来的商品价格,商品在日常售卖的价格是 5元,当在某些指定场景 或 时间下,售卖价格是3元。 这里5元就是商品原价,3元就是商品的活动价格。
活动可以是面向B端商家的(曝光,流量),可以是面向C端用户的(降价,补贴),而活动本身的形式又是多样的。
单品活动,即只作用在单个商品上的活动,不管是单独购买这个商品,还是购买多件商品中包括这件商品,都可以享受一个固定的活动价格,而不会因为购买了其他商品,导致以一个特殊的价格购买这个商品。
举例1:商品A,日常售卖价格是5元,由于店铺周年庆,推出半价购买的活动,即在店铺周年庆当天,顾客将以2.5元的价格购得。 店铺周年庆当天商品A以半价销售,就是单品活动。
举例2: 商品A,日常销售价格是5元,由于店铺周年庆,推出店铺内商品买够4件,商品总价打6折,虽然A可以用3元购得,但也不是单品活动,属于多品活动-N件M折玩法。
1.2 电商场景中单品活动的表现形式
日常电商软件中的,秒杀价,百亿补贴价,折扣价,都属于单品活动领域范畴,具体价格,也由单品活动的系统服务来计算,
所以,单品活动服务也在整个交易链路中起到支撑作用。
由于电商活动商品本身是有权重加权,所以用户打开APP第一眼看到的几乎所有商品的价格都是由单品活动服务计算。
2 架构演进
2.1 单体服务
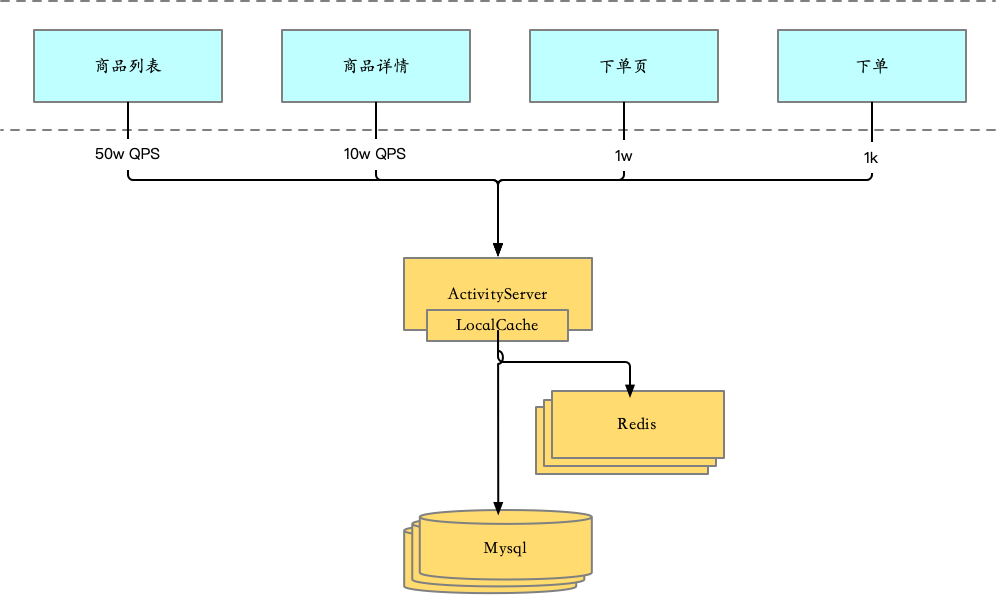
单体服务的时候,整体架构比较简单,一个带分库分表的Mysql集群,一个Redis集群,在加一套本地缓存,基本能扛住大几十万QPS。具体链路使用资源分配如下:
| 链路 | LocalCache | Redis | Mysql |
|---|---|---|---|
| 商品列表 | 使用 | 使用 | 使用 |
| 商品详情 | 可选 | 使用 | 使用 |
| 下单页 | 可选 | 使用 | 使用 |
| 下单 | 可选 | 使用 |
服务个场景的响应时间
| 链路 | 平均RT | 999 RT |
|---|---|---|
| 商品列表 | 25ms | 50ms |
| 商品详情 | 3ms | 18ms |
| 下单页 | 3ms | 18ms |
| 下单 | 5ms | 20ms |
如果业务发展,整个服务如果达到百万QPS以上,比如当前(mark 2023-07) 整个业务服务QPS达到了300万,该架构整体消耗的资源将会变得巨大。根据大概的流量漏斗特性,如果整个业务服务达到300万QPS,列表场景的QPS将达到 240万,理论上 至少需要480台机器支撑。
计算步骤:单实例Dubbo线程200,999RT 30ms, 单实例日常30%水位。 2,400,000 / (200 * 1000 / 40) * 30% = 1600 台
那为什么RT会比商详场景的高呢?主要原因在于 商品列表场景,对是按照goodsId批量查询数据的,而Mysql是按照goodsId纬度分库分表,所以当多个Redis未命中的时候,需要把每个goodsId进行回表查询 ,并且每个goodsId要查询多个表 才可以拼凑出完整的活动实体。
2.2 CQRS改造
其实不能严格的算CQRS,但如果把商品列表场景单独拉成一个服务来看,对于这个服务,又像是CQRS架构。
主要做了以下几件事情:
- 由于80%的流量都来自商品列表场景,而本身商品列表场景 和 商品详情/下单流程 场景的保障级别不同,对数据延迟的容忍度也不同,故单独拉一个服务出来支撑商品列表场景。
- 为了减少一个GoodsId对应活动价信息的回表查询,努力做到最多只回表一次的结果,考虑异构一套数据出来,并且针对goodsId纬度,将单品活动领域实体压缩到一条数据里,将关系型数据压缩成kv结构的数据,即
goodsId:{xxx,xxx,xxx}这种形式 - 针对压缩成kv结构的数据和读多写少的特性,异构数据选择nosql类型的存储(nosql可以更好的支持分布式),最终选择了HBase作为存储载体。
所以整个架构就演进成了:
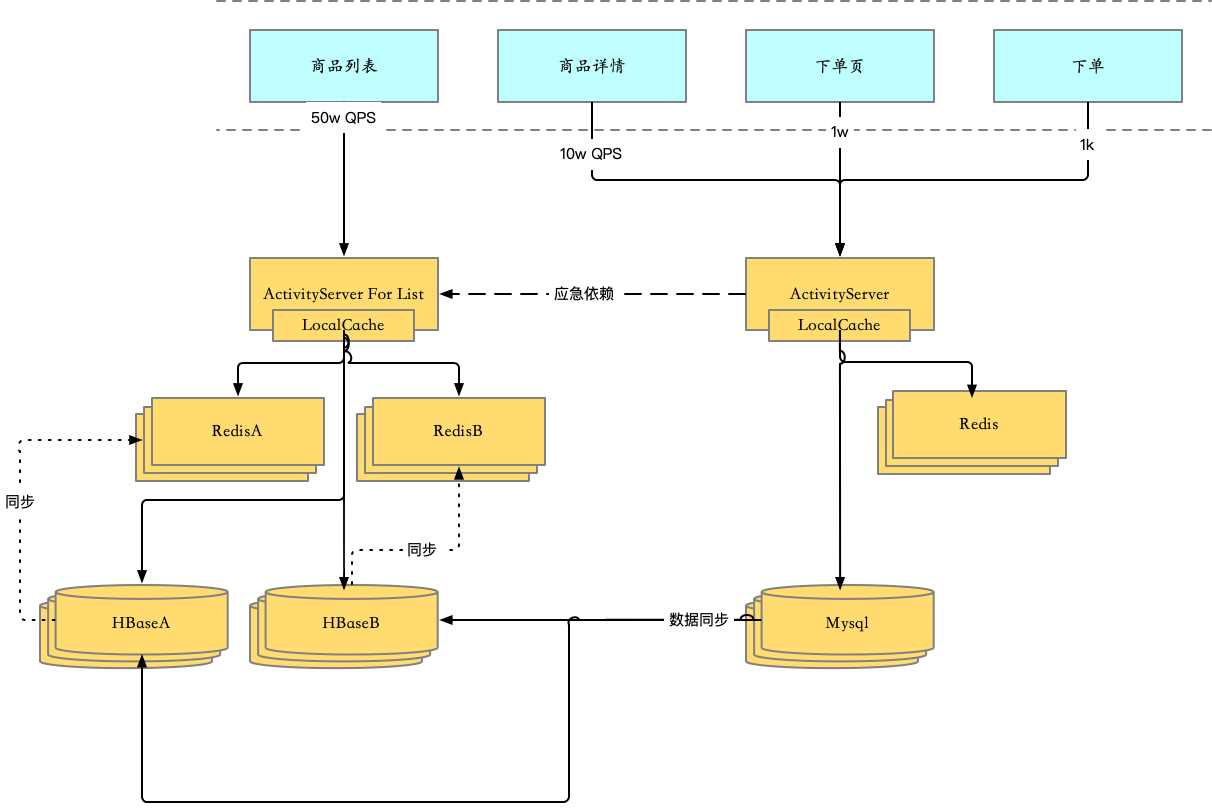
这里为什么有两套HBase集群?
- 这两套HBase集群互为热备(50%流量到A,50%流量到B)
- 如果A集群出现问题,可随时将流量全部切换到B集群。
- Redis集群同理。
这里为什么下单链路没有双Redis保障?
- 如果下单链路Redis出问题,可执行的手段:1. 将商详流量切到应急依赖上(依赖ForList服务);2. 将Redis摘到,将下单页和下单流量完全打到DB上。
改造之后,整个系统RT表现
| 链路 | 平均RT | 999 RT |
|---|---|---|
| 商品列表 | 5ms | 20ms |
| 商品详情 | 3ms | 18ms |
| 下单页 | 3ms | 18ms |
| 下单 | 5ms | 20ms |
2.3 多机房建设
按照上述的架构,如果Redis集群或者HBase集群故障,整个服务将不能对外提供能力,
2.3.1 读多活改造
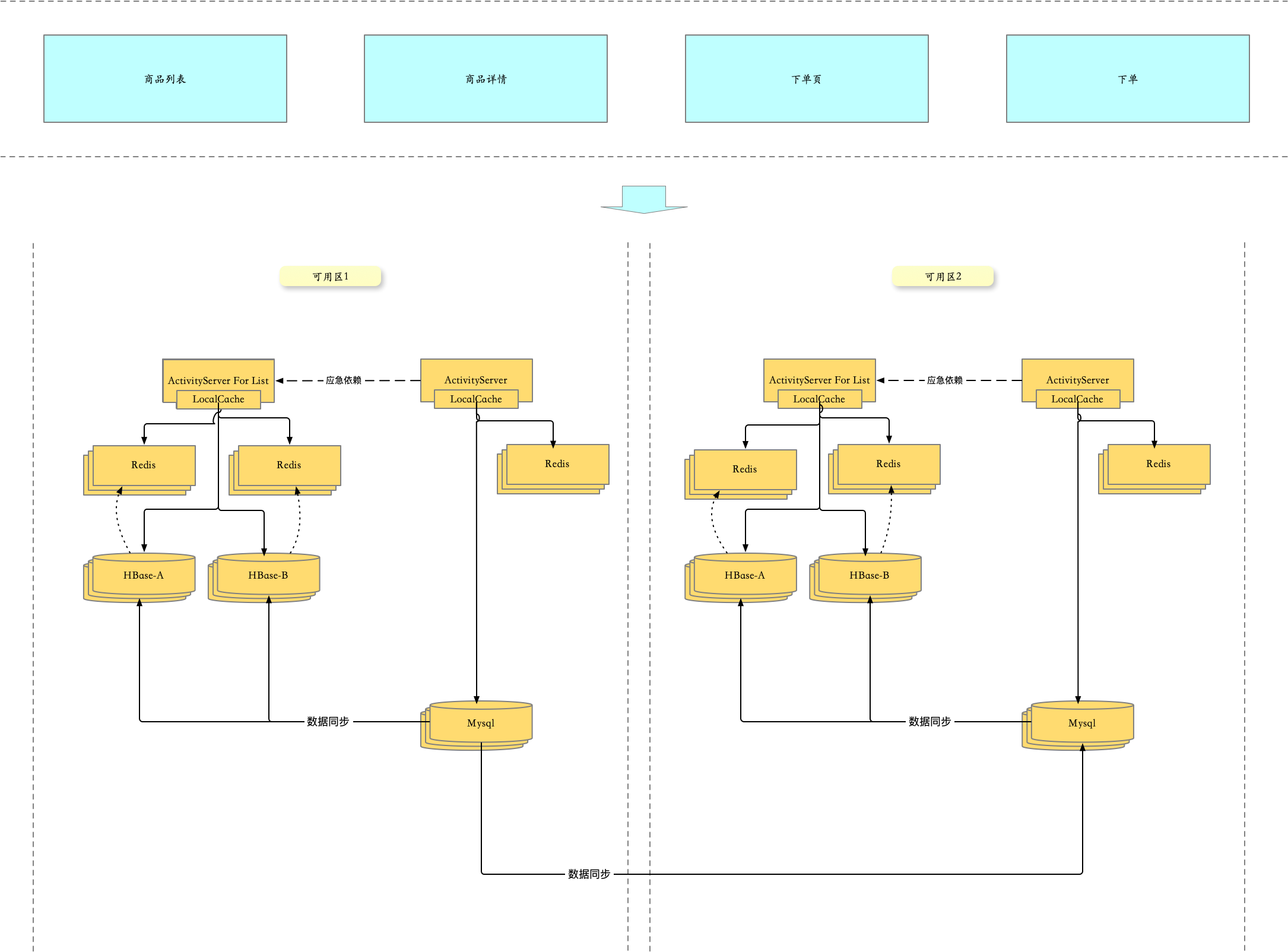
这样改造之后,能够保证,如果可用区1 内部组件 or 网络出故障之后,能够将上游流量切换到可用区2。
问题:
- 如果流量都切到可用区2,就要日常保障可用区1和可用区2 整体资源要对等,特别是主要抗流量的资源(比如 服务容器、Redis集群)等
- 如果是可用区1 的Mysql出现问题,虽然整体业务能够正常运行,但由于可用区2所有冗余的数据源头是可用区1的Mysql,所以会导致整体服务 数据不会被更新。
2.3.2 写多活改造
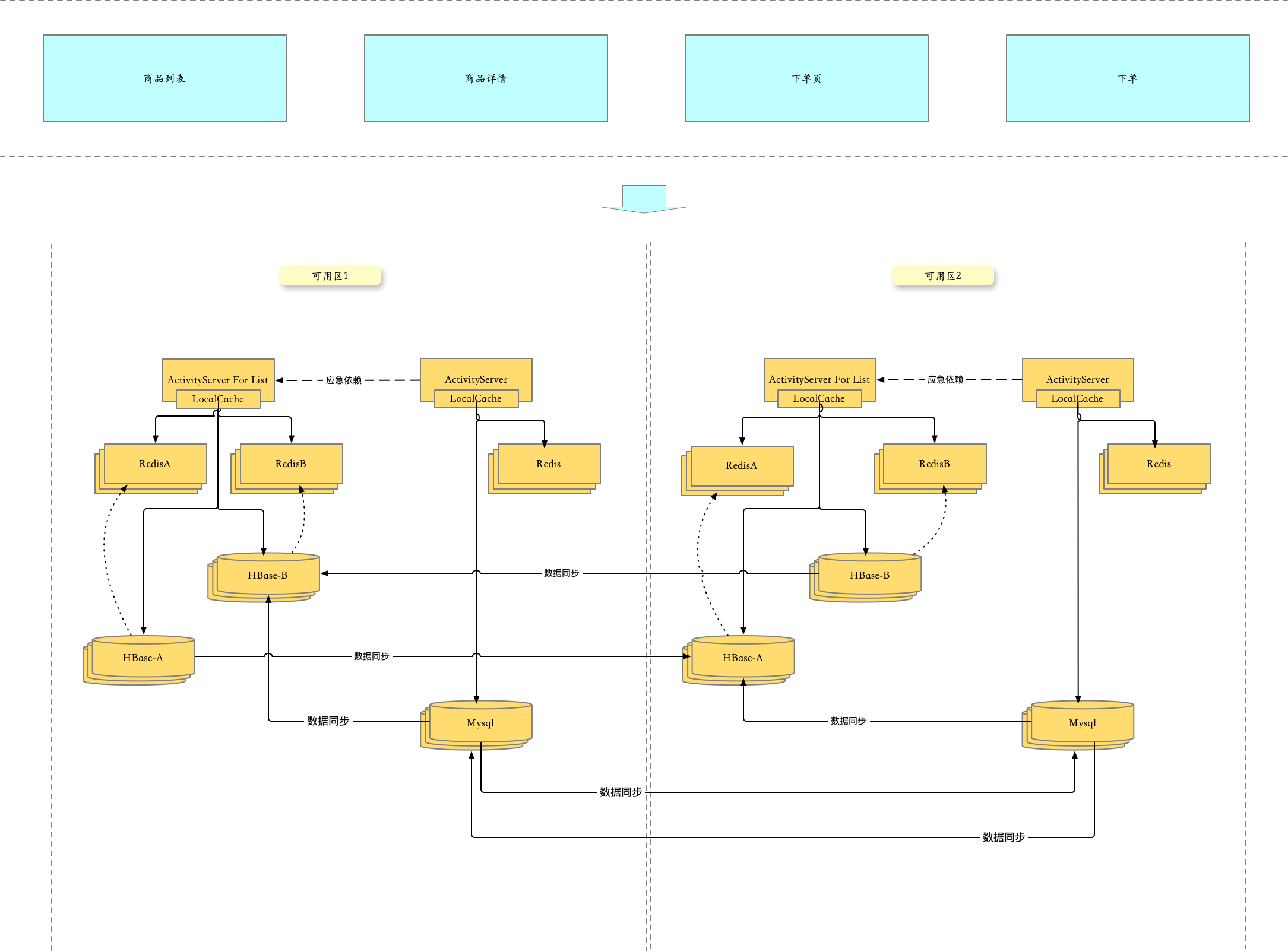
这样改动之后,基本可以达到任何一个节点挂掉,按照如下切换原则,可以持续支撑业务。
- 商详、下单链路上的节点出问题,ActivityServer 切流,ActivityServer For List 不用动
- 列表链路上的节点出问题
- 可用区1容器故障:可用区切流
- 可用区1RedisA故障:流量切换到RedisB
- 可用区1HBaseA故障:流量切换到HBaseB
- 可用区1Mysql故障
- 可用区切流
- HBase切流
- Redis切流
3 稳定性建设
3.1 数据一致性保障
3.1.1 数据监控 & 数据纠错 & 数据恢复
这里数据监控和数据纠错&数据恢复一起说,因为当监控到数据错误的时候,可以顺便纠正,而纠错的范围如果是全量的话,也可以称之为数据恢复。
由于异构数据链路存在,需要对数据一致性进行监控,主要分为:
| 保障场景 | 保障一致性 |
|---|---|
| 列表场景 | HBase,Redis,Mysql |
| 商详、下单页场景 | Redis,Mysql |
实现数据监控的手段主要有两种,一种是全量数据一致性校验,一种是增量数据一致性校验。
而整个 纠错/监控 系统可以划分为两部分,第一部分是 触发、第二部分是 处理,两个系统通信可以通过MQ。
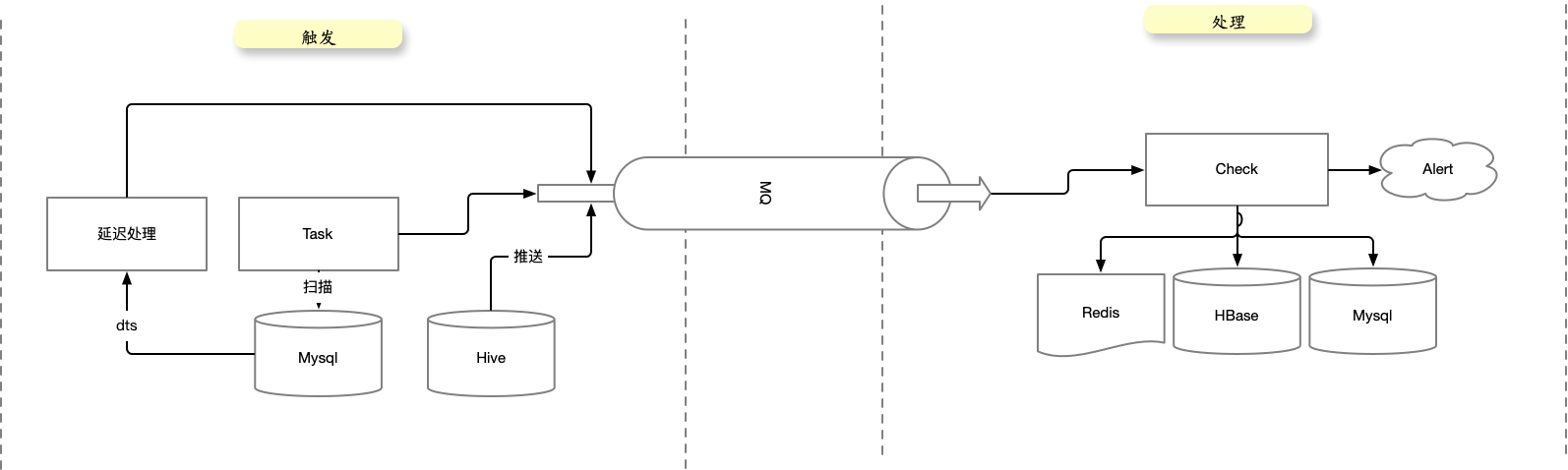
这里主要有三个触发源,DTS延迟处理 和 Task 扫描最近一段时间变更的数据都是增量处理方式。Hive推送是全量处理方式。
- Task 扫库本身是对DB有压力的,所以建议使用DTS延迟处理。
原则:
- 触发源做不同阶段的触发,也可以做特定业务逻辑(比如针对重点活动做保障等)。
- 处理系统只需要做当前数据的比对和处理。
3.2 逻辑准确性保障
逻辑准确性保证,主要目标是在迭代复杂业务代码逻辑的时候,出现bug。由于价格计算的对与错本身很难被发现,出现逻辑bug的影响通常是长期的,严重的。
3.2.1 价格计算结果监控
针对结果进行监控,首先要针对结果找到不同的特征,然后划分为不同纬度,比如:活动类型维度、业务玩法维度、条件类型维度、价格区间维度、活动标签维度、业务身份维度 等等。然后再制作这些维度的走势统计面板,并根据 日、周,同比、环比,曲线进行监控,并设置相应的波动告警。
3.2.2 价格计算过程监控
针对过程进行监控,首先要梳理过哪些场景,在出价格的过程中做了哪些事情。比如 什么场景从哪里查询了数据,进行了哪些过滤逻辑,丢掉了哪些特征的活动,最终才选出了一个最优的活动。这些过程同样可以制作统计面板,然后再根据 日、周,同比、环比,曲线进行监控,并设置相应的波动告警。
在上面的基础上,我们还重写了一份用于验证过程和结果准确性的代码,对不同接口场景的请求参数、返回值、逻辑上下文进行抽样,并以MQ的形式发送到专门用于验证准确性的服务,做逻辑准确性验证。
4 总结
根据单品活动服务本身属于靠近底层的平台服务,但由于价格跟业务强相关,在具有足够大流量的同时,又有足够复杂的业务逻辑,所以在服务设计上,即要保证平台服务的架构稳定性,又要保证复杂业务的准确性,整体挑战还是较大的,但话又说回来,只要保证上述两个大方向,就可以安全顺利的进行业务迭代。