店铺架构CQRS改造
店铺架构CQRS改造
背景介绍
首先介绍下我们店铺组整个领域, 如下图:
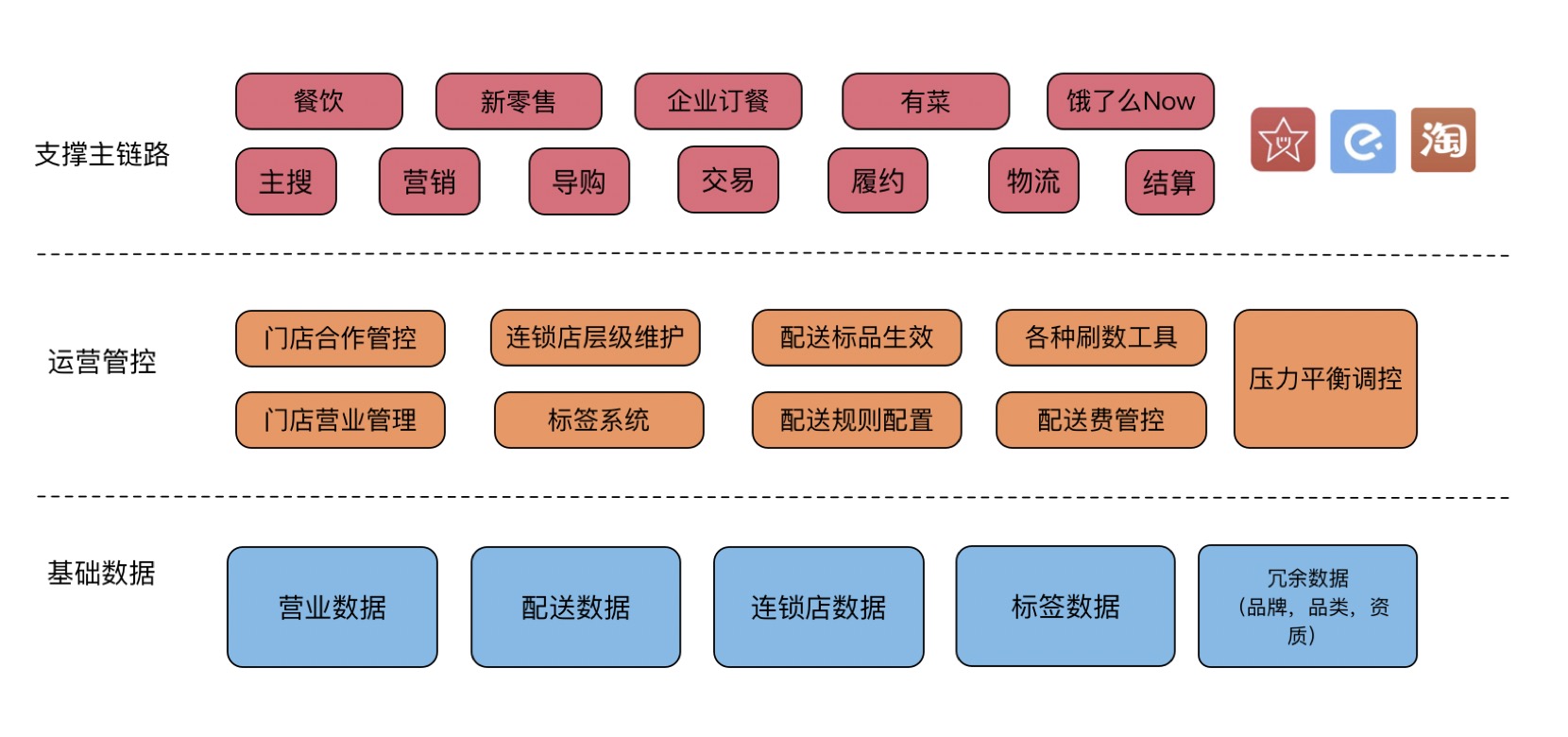
店铺组负责店铺数据生命周期的管理, 从开店开始到店铺被注销无效掉,整个过程都在店铺这边管控,负责店铺运营。其中业务可以分为面向B端的数据录入维护,面向C端的数据输出,而C端输出的相比起来更为重要,流量大,且不允许有任何抖动。
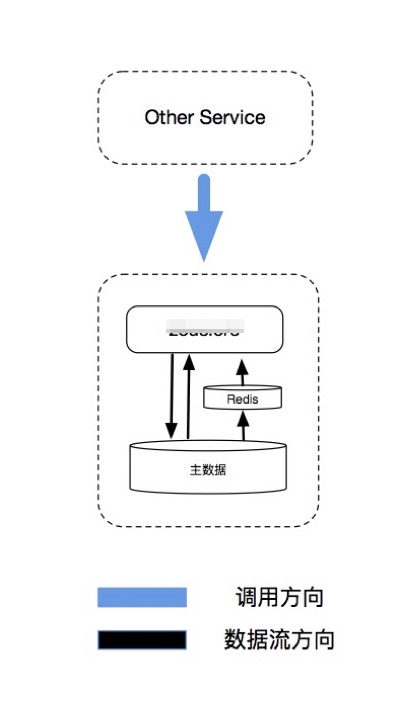
这是改造之前的服务架构简单化后的图,只有一个核心服务再支撑B端业务和C端业务,服务在DB之上做了缓存来保证对高QPS的支撑。
相关问题
上面这种架构在发展过程中会暴露出一些问题,我们一一列举下:
- 核心服务变更频繁
我们都知道,B端业务发展更迅速,产品提需求的频率更高,代码变更发布就会更加的频繁,针对上面这种架构,所有变更都会直接导致核心服务的发布,而服务变更次数多又是导致服务稳定性低的主要原因。
- 代码逻辑复杂,服务性能差
店铺数据对C的能力归根到底就是给一个店铺ID,给出这个店铺相关的数据。而B端的业务就不会这么简单,比如定时开关店,根据创建时间查询店铺列表,各种定制化的复杂变更和查询层出不穷。
为什么服务性能差呢? 一台服务器能提供的服务线程数是一定的,比如是100个线程。 如果一次请求的相应时间是100ms,则100*1000/100得出的这台服务器能承担的最大QPS就是1000, 如果在请求中,有些请求走了复杂的逻辑,复杂的数据库查询语句,导致这个请求相应时间是1000ms, 如果这种慢请求的qps是10,那么100个线程就要在1s内拿出10个线程来处理这种慢请求,即剩余90个线程, 90*1000/100 + 10 == 910 QPS, 这样基本每台机器少了100qps的吞吐能力,当然我们根据日常监控来看,核心接口的qps都在3ms左右, 那这就不是100qps的差别了, 甚至涨到了上千qps的差别。
- 服务资源浪费
资源浪费的道理跟第二个问题是一样的,一台机器的吞吐量降低了, 要支撑同样的吞吐量,就只能扩容机器,所以资源就会被浪费
解决方案
那么怎么解决这个问题呢? 很简单的就是想到把B和C的业务逻辑区分开,把C端高性能的接口都凑到一起,把B端的接口和能力全部打包到一个B端服务上,这样做的好处就是B端服务的问题不会扩散到C端服务上去,而B端服务可以频繁变更,也不会因为变更频繁而导致C端主业务崩溃。
下面我们看下系统架构:
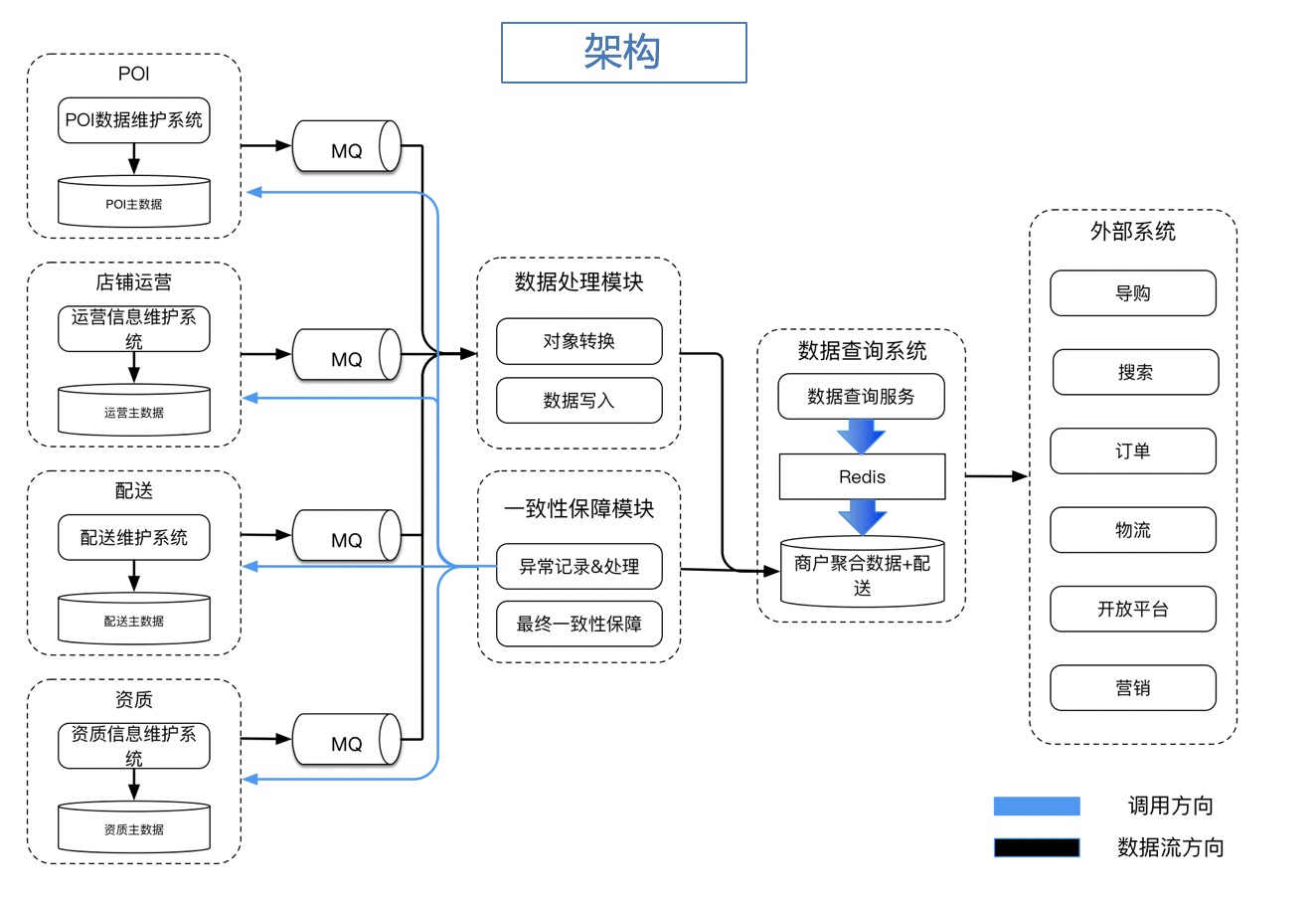
这个架构图中第一列就是B端服务,每个服务都是一个单独的领域,有单独的开发,产品维护,变更频繁;图中的第三列(如果MQ算第二列的话) 是数据处理模块,数据处理模块将B端服务的数据做聚合,比如将poi,资质,运营的数据全部通过数据处理模块聚合到一张以店铺id为纬度的表中;第四列数据查询系统就是所说的C端系统,这里只负责简单逻辑的查询,先从Redis中查,查不到从DB查,然后full Redis,尽可能少的数据模型映射,比如就PO和DTO两层, 这样能够减轻java的GC压力。
这张图中你可能会有疑问:
- 为什么要做数据聚合,B端和C端用一份套数据是否可以?
如果做了数据聚合,那么B端数据和C端数据就不能用一套了, 因为B端数据都是单领域的,比如门店运营数据中不会有POI的数据,但是C端查询一般不关心这个数据到底是poi数据还是门店运营的数据,所以做一层店铺纬度的数据聚合,能够更方便别人使用。
那么B端和C端用一套数据是否可能? 这里不建议用一套,因为如果用两套数据就可以做到B和C之间的完全隔离, 包括数据库的抖动,都不会有联动,这样使得解偶达到最大化。
- 为什么B端数据到C端聚合数据的同步是使用MQ?
MQ有两个好处,一个是异步,这样能够保证解偶,另一个是平缓削峰,这样数据处理模块不会因为B端服务的变更过于频繁导致处理崩溃,或者阻塞B端服务正常运行。
- 既然同步是异步的,C端查询服务的数据实时性怎么保证?
答案是不保证,说实话,C端查询服务确实保证不了数据实时性,但对数据实时性要求搞的请求完全可以去B端服务查询,而且使用C端查询服务的也应该接受秒级别的延迟,映射到店铺领域,店铺名称改了,在饿了么App上延迟1秒展示出来也没有问题。
- 中间多做了一层数据同步,如何保证B和C的数据一致性,C-DB和C-Redis的数据一致性?
这就是真正要解决的问题
我们先说如何保证C-DB和C-Redis的数据一致性, 这个我们首先做了异步比对,比如每次C-DB发生变更都会通过公司中间件广播消息出来,然后根据消息做抽样检查,比对DB和Redis的一致性,如果不一致频率很高会高级出来,而且发现不一致会自己在同步刷一遍Redis
我们再说如何保证B和C的数据一致性,这个就是定时的拉B端变更的数据,然后将B和C关键的数据做一致性对比,不一致同样是告警+修复
最后我们做了一键同步的工具,如果出现问题能够保证在5分钟内全同步完
- 由于消息消费是异步的MQ,如何保证消费顺序的问题
消费顺序有两种思路,第一种就是在B端服务加全局乐观锁,消费的时候根据乐观锁版本号判断消息新老,这个我们配送服务就是这样做的,缺点就是锁整个领域成本太高了。第二种思路就是在数据处理模块做锁,这样就不会阻塞B端领域的玩法,具体做法就是每次收到消息后按照店铺id上锁,锁住之后select b端领域的数据,然后更新聚合表,然后释放锁,这种做法也是有弊端的,就是分布式锁并不可靠,所以要想好降级策略,最后就是还有个小窍门,如果B端消息实在是太频繁了,可以用滑动窗口来做聚合,保证别把聚合库写挂了
结果
这个改造结果还是蛮明显的,可以让核心服务更稳定,就是解决了上面的问题,而且我们C端查询服务的QPS现在有近400K,300多台8C16G的服务在支撑这,平均服务RT3ms
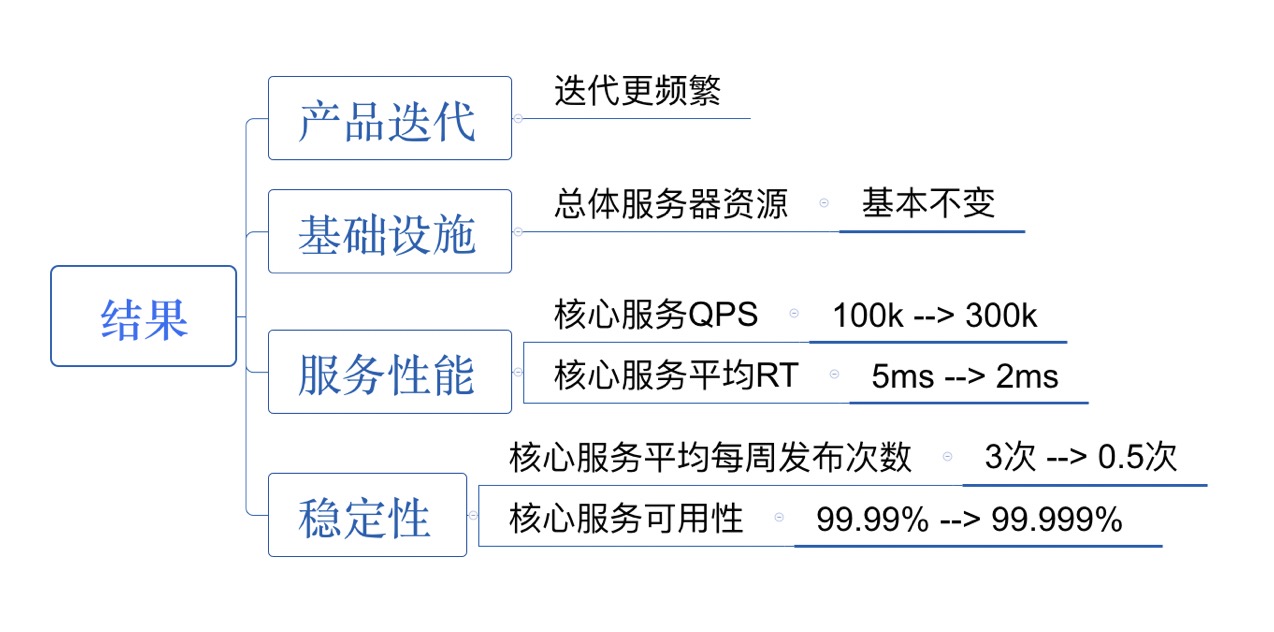
上面的图大致列了下成果,但当时的QPS是300k,现在不到一个月已经涨到近400k了😂