饿了么店铺组备战双十一记事
饿了么店铺组备战双十一
0 背景
饿了么 被阿里收购之后, 作为阿里本地生活战略布局中重要的一环, 有幸参与到双十一这一重大活动当中, 这也是饿了么第一次接受阿里集团其他产品线的流量引入,双十一当天具体能有多少超日常流量的额外流量被进入饿了么是无法预估的。 如果当天因某些原因(特别是流量增长)导致服务出现波动甚至是宕机,将会造成巨大的损失。
店铺服务作为饿了么关键链路上重要的一环, 直接承载用户流量,如果出现问题将直接导致公司所有外卖产品线的崩溃(饿了么外卖,星选外卖,手淘外卖,新零售产品线),这锅真的是背不起, 更不想再次上演915事件。
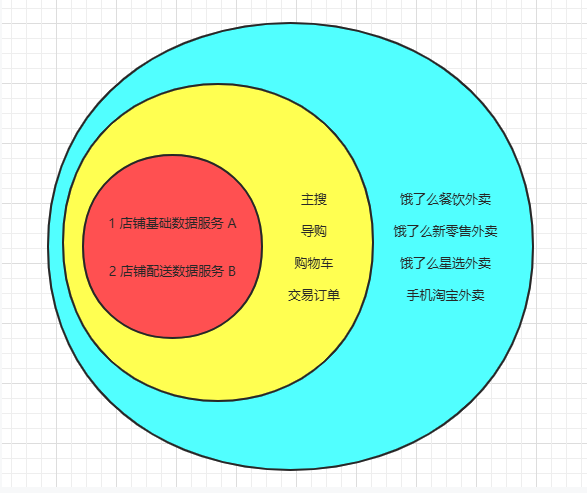
如图,红色圈是店铺组提供的服务,在关键链路上有两个服务深度耦合进去, 一个是店铺的基础数据服务A, 提供店铺基础数据,如店铺营业信息,店铺资质信息, 店铺POI信息等, 主搜和导购对店铺基本数据都分别有落地和缓存,所以并不算强制依赖, 但是进店, 加购物车, 交易下单等都会实时调用查询店铺的营业信息等。 另外一个是店铺的配送数据服务, 提供实时的配送信息计算,包括能否配送/配送费/配送团队等, 由于计算逻辑复杂且对实时性要求极高,所以导购,购物车,交易下单都会实时调用服务B。 这两个服务如果有任何一个出现问题,都将会导致严重问题。
我们要做的就是在双十一当天(平时也是)确保服务A和服务B的稳定, 如果在双十一当天真的有流量洪峰, 绝对不能作为水桶的那根短板, 就算挂,也不能第一个崩掉,就算第一个挂掉,也要在短时间内恢复。
1 事前
其实为了备战双十一, 我们在还有两个月左右的时候就开始准备了, 当然也不单纯是为了抗双十一, 主要目标借这个契机提高服务的整体稳定,把一些缺失的东西补上来, 形成一套面对类似情况的方案。
双十一之前我们做的一些事情大致可以分为几点: 限流、降级、压测、监控、容控、预热 下面分别说一下
1.1 限流
做限流就是挡住过多流量,以防流量洪峰把服务打垮, 因为我们是最底层的服务, 如果触发限流, 多余的流量必然会引起异常,使部分正常用户流量被拒之门外, 但能保证服务不全挂, 大部分可用。
1.1.1 方案
公司基础框架提供对服务层面的限流, 限流的最细粒度是:客户端服务+服务端集群+服务接口方法, 由于平时并没有超过服务能力的流量进来, 所以对限流操作并不熟悉, 这次借着双十一准备,也算是体验了一把公司框架提供的限流能力的玩法, 最终以文档的形式落地输出, 供以后使用。
对于流量上限的评估, 我们是以平时压测所压到的最高流量作为限制,然后把限流配置好,状态关闭。 如果出现因流量问题导致的服务压力过大,可以一键开启。
1.1.2演练
我们先在测试环境演练测试一波,确定限流功能ok的情况下,在晚上22点以后, 业务低峰期的时候, 将限流上限调整比当前流量高一点点, 打开限流, 如果发现有被“拦截”掉的流量,就立刻关闭限流开关, 得知功能可用即可, 调回原来的流量上限
1.2 降级
降级:就是在必要的时候把不必要的东西弃掉, 这个也是有一定紧急程度的,保住重要的,丢弃相对不重要的。
我们把降级分成两大类:服务降级、业务降级。而服务降级又分为客户端降级和服务端降级。
1.2.1 服务降级-客户端降级
客户端降级的意思是客户端服务将对某一个/几个服务的调用丢弃,这些降级有些是有损的,有些是无损的, 根据损失程度不同,也可以分为多层降级。
我们B服务计算配送费的时候, 会调用营销的接口获取配送费补贴, 拿到配送费补贴后在基础配送费上面减去补贴将结果返回给前台。 这样就存在: B服务 -> 营销服务的调用链路,为了提高配送费计算的准确率,这条链路上面还有一层快速失败重试的逻辑,我们在讨论问题的时候,发现如果营销服务延迟变大,导致B服务对外提供接口的相应时间被拉长,从而会导致B服务性能下降,影响订单交易。最终我们对B服务做了两层降级方案:
- 必要情况下去掉快速失败重试逻辑
去掉快速失败重试逻辑会保证大部分的订单配送费计算准确, 少部分配送费无法计算补贴。 当营销服务在未崩溃的情况下,可以用下调快速失败逻辑保证B服务的性能不会太差。
可以这样理解: 营销接口响应时间平时是10ms, 网络抖动会导致延迟超过100ms, 我们把超过100ms的请求快速失败+重试, 这样就会降低营销计算失败的概率,也不会影响上层服务的性能。 如果营销服务出现问题, 导致大部分接口响应时间超时, 上层服务会重试加重营销服务的压力,而且也会拉长上层服务的整体响应时间,造成连锁反应。 所以如果发现营销服务超时请求突增,可以考虑去掉重试逻辑, 保证上层服务接口性能在100ms内。
- 必要情况下去掉调用获取营销补贴的逻辑
当营销服务已经崩溃的情况下, 为了不让B服务被殃及, 在计算配送费的过程中直接丢弃补贴计算,这样虽然是有损的,但是不会因连锁雪崩造成更大的损失
上面两个降级的触发都是在双十一之前配置好并且处于关闭状态的,如果出现问题, 可以做到一键降级。
1.2.2 服务端降级
服务端降级就是不允许客户端调用了, 这种可以根据流量百分比降级, 比如100K的流量打进来, 服务端降级流量10%, 到最后会有90%的流量打到服务端,10%的流量就直接拒绝掉了。 当然也可以不拒绝这10%的流量,而是直接将这10%的流量转到默认方法上, 不走底层业务逻辑,直接返回特定的值。
我们在B服务计算配送费上做了两层服务降级, 一层是导购侧计算配送费接口降级,一层是交易订单侧计算配送费的降级, 这两个降级都是直接返回一个随机数(当然随机数的范围是可配置的)。 第一层降级损失比较小 , 只是展示上的问题,第二层降级就涉及到支付结算的钱了,所以第二层只是出了个方案,我们支持,但是不到万不得已,绝不敢操作的。
1.2.3 业务降级
我们还订了一些业务方案的降级,一些业务批量操作,异步任务在当天都做禁止使用,批量操作是给BD或者运营人工触发的,不确定性比较多,比如触发时间不确定,触发数据不确定,异步任务虽然触发时间是确定的,但是每次触发后执行时间长,数据量大,为了缓解当天DB的压力,也为了避免批量操作导致缓存失效,造成缓存穿透,最终决定从11月10号开始停止部分批量操作功能,11月11号与12号停止部分异步任务(这些任务一定要幂等的才行)
1.2.4 演练
我们只做了服务降级的演练,因为这些服务降级的开关都是新加的,没在线上验证过, 所以打算在业务低峰期的时候 在线上做一次降级,每次降级1~2分钟,验证降级ok后就关掉降级开关。
10月18日 23:17 我们对列表页配送费计算做了客户端降级(丢掉营销补贴)2分钟
我:晗哥 主站列表页我开始降级配送费营销补贴了
防晗:开了?
我: 开了
防晗:我看调营销接口的曲线咋还有呢? 是不是不起作用啊。
我:在等等, 是不是有延迟。
防晗: 再等等不会有客诉吧?
我: 再等一分钟。
防晗: 来了, 曲线掉底了,赶紧关。
我: 关了
10月18日 23:26 我们对手淘外卖列表页配送费计算做了服务端降级(丢掉计算逻辑)2分钟
我: 服务端降级开搞啦~
防晗: 降谁啊?饿了么主站?
我:我靠,降饿了么主站肯定会出客诉的, 人家晚上订餐一看配送费全部8块钱,不怪吗?
防晗: 你多配置几个,7块,7.5块 8块 随机展示
我:要不我们试下降手淘外卖?
防晗: 好
我:开始了, 你看看手淘外卖的列表页的配送费。
防晗: 来了, 配送费全是7,7.5,8
我:你看下单配送费计算的对吧?
防晗:嗯 对, 下单没有降
我:ok 关了
1.3 压测
在双十一之前,我们做了很多次压测, 有跟着公司全链路一起进行压测的, 有我们自己单独压测的, 由于我们是多机房部署,所以每次压测都是对单机房压出平时全机房业务高峰期的流量, 应对业务高峰期出现全机房切换的情况。
这次我们压测主要是分成了两种方法,一种是单服务压测,一种是多服务压测, 目标是对单机房压出高峰期全机房2倍流量
1.3.1 单服务压测
单服务压测是对本服务所能承受的压力进行压测, 在店铺组 A服务和B服务都承受着主站流量的冲击,我们分别单独对A服务和B服务进行压测, GET接口平时全机房业务高峰期共50K, 我们这次压到了100K, MGET接口平时是15K, 我们这次压侧压倒了40K的QPS。
当然在备战双十一最后一轮压测之前,店铺配送服务 做了好几轮优化,代码和缓存存储方案上的优化,Redis中间件团队对该集群的优化, 使得该服务接口性能得到了明显的改善:从单机房MGET为9KQPS, 接口响应时间进20ms, Redis集群网卡快被压爆; 到单机房20K,响应时间不到10ms,部分Redis机器触碰流量红线;再到单机房40KQPS,还没有触碰Redis网卡流量红线。关于配送的压测经历,后面我会单独写篇文章来记录。
1.3.2 多服务压测
多服务压测就是对多个服务并行压测, 这次不是为了压单服务的性能, 而是为了压共用组件(如共用Redis集群,共用DB集群)的压测。
压测除了配送B服务有些性能瓶颈且有优化方案之外, 也没有发生其他的什么问题。
1.4 监控
双十一监控大屏和告警是必不可少的,虽然公司有自己的业务大屏和NOC团队,但我们也借此机会梳理了我们店铺组内部的监控大屏和告警。
1.4.1 大屏
我们把大屏分为两类,一类是对C的接口大屏, 一类是对B的业务大屏。
对C端,我们只是单纯的提供基础数据的读取接口, 特点就是QPS高, 对缓存和DB的压力大。 所以我们主要关心:接口QPS、接口响应时间、Redis性能、服务异常,四个维度。
对B端,我们要关心业务完成度,某个业务从开始到结束可能需要与多方交互, 在这之中可能有些异常场景会被触发。 所以我们关心:业务执行完成数量、业务执行失败数量、触发某些特定场景的数量、依赖接口的性能、异常等。
下面是我们多个大屏中的一个:
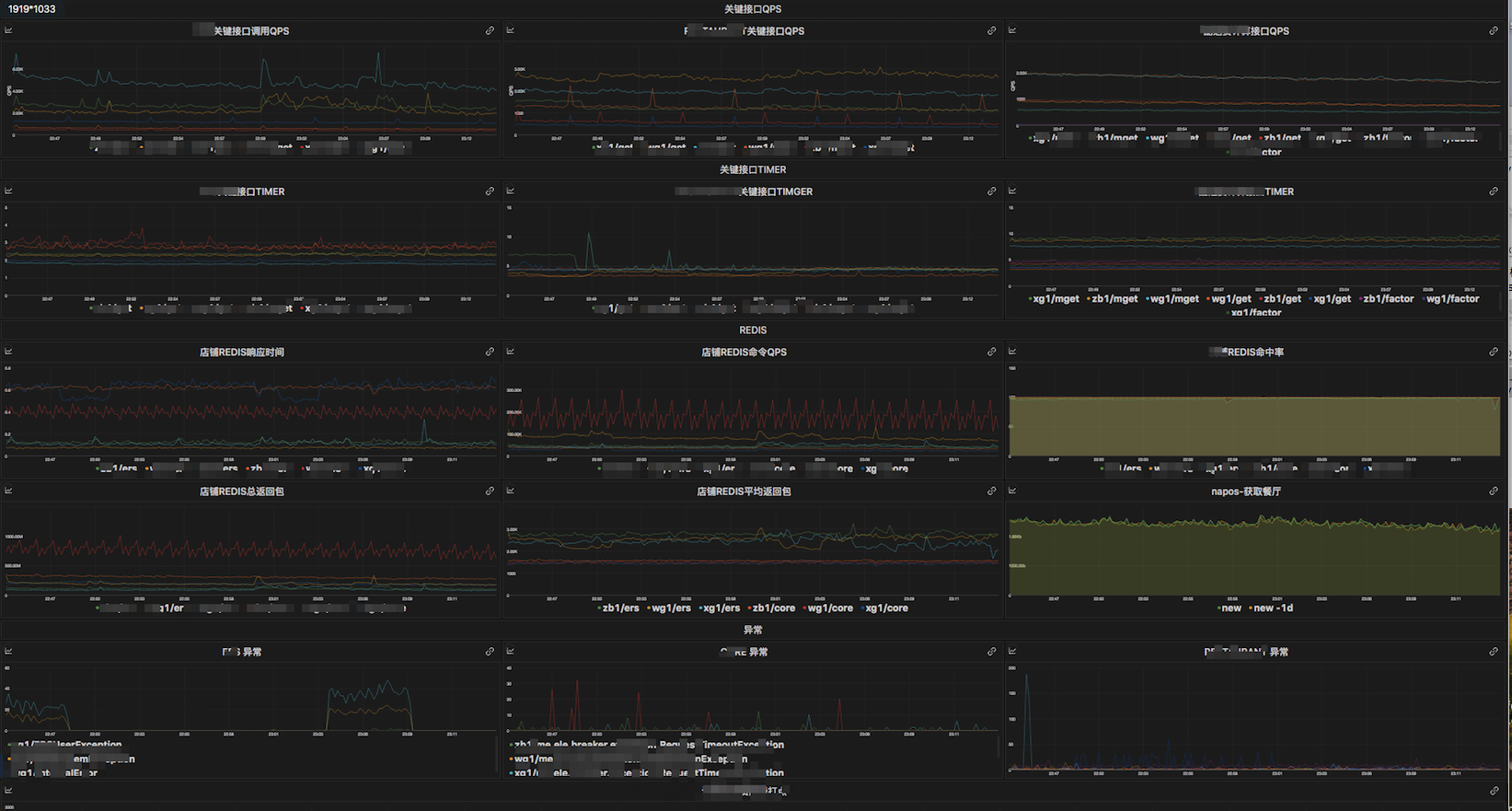
不得不说,饿了么的监控设施做的是真的好!
1.4.2 告警
我们新增了很多相关告警, 最重要的短信告警, 次重要的钉钉告警。
比如 对C端的接口告警, 如QPS过高,QPS突增,QPS掉底,接口响应时间超阈值,服务JVM性能异常, 服务异常超阈值等
比如 对B端的业务告警, 如业务逻辑触发特定异常, 定时任务未触发, 服务异常过多等。
1.5 容控
容控: 是组内对服务容量的控制,每个组的容量根据业务的重要性基本是申请完不会变的,除非特殊情况可以申请扩容。
在双十一之前,我们大致梳理了 组内空闲的服务资源, 对一些不重要的服务/集群做一些缩容, 对重要的服务/集群进行相应的扩容, 并且流出一定的空闲预算,以防当天出现服务容量不足,在申请资源的过程中可以先拿空闲资源顶上去,避免资源申请时间较长耽误扩容。
1.6 预热
预热方面做的事情大概可以分为 资源预热,操作预热,人员预热。
资源预热主要是Redis资源预热,因为QPS高的服务都是以命中缓存来缓解DB的压力, 所以在双十一头几天, 我们讨论要不要将Redis缓存过期的时间调整的长一些, 虽然觉得可以调整,但是后来没有去做(主要也觉得要发版调账,万一没玩好,再搞砸了就不划算了)。当然还有一个方案,是想在10号晚上22点左右的时候,把缓存全部刷新一遍,这样就可以避免11号当天出现大量缓存过期而导致问题, 这个也没有做, 因为观察了历史,发现我们缓存过期的时间点还是比较分散的, 基本全天Redis命中率都在99%以上, 早晨7点~7点30分会有一波较多的key过期,命中率会降到96%左右,觉得不会有问题,就放弃执行了,毕竟全量刷key的风险更高一些。
操作预热就是各种演练,各种操作文档落地(为了双十一,真是落地了很多平时不太注重的操作文档!)
人员预热:安排组内值班,渲染氛围,公司双十一之前发了很多零食, 我们自己都存了好多出来😂
2 事中
由于11月11日是周日, 我们组小伙伴在11月10号晚上8点就开始去公司值班, 把之前准备好的几个大屏分别展示在显示器上,然后观察大屏曲线有没有波动,有没有异常告警。
我自己也在家把关键大屏摆在了显示器上,一边看大屏,一边看天猫晚会。 然后等11月11号零点来了, 在抢购的同时看看大屏曲线是否正常, 一直到凌晨两点左右,觉得没有问题,便睡觉去了
11月11号早晨8点开始 到晚上9点是我值班, 经历过午高峰和晚高峰两个订餐高峰期后, 觉得没有问题便欣然回家了。
3 事后
这是饿了么首次加入天猫双十一活动, 除了店铺组, 整个公司都在为此准备压测、降级方案, 我个人觉得不管双十一给饿了么带来了多少流量, 不管是否真的有比平日高的流量高峰进来,但是对于任何一个参加的团队而言都是查缺补漏的一个契机,就像店铺组:我们计划了一整套面对高流量的操作方案(虽然期望着永远用不上),完善了组内自己的监控和告警,使得自己有备无患,面对类似的突发状况也能有个匹配上的操作方案,我觉得这些才是我们技术团队收获的,当然当天具体多了多少订单我是不知道的,如果收获“超过竟对的这个结果也是极好的。
4 感谢
至此,店铺组双十一备战记事便完事了,这是我工作以来第一次参加到如此大规模的备战准备上来,感觉非常幸运。
感谢组内leader和所有小伙伴,在与大家一起讨论中成长!
感恩!